DAOGolemDBManager
An interface for uploading, searching, and downloading files using GolemDB for DAO usage.
- 100 Raised
- 611 Views
- 1 Judges
Categories
Gallery
Description
Bounty: GOLEM DB
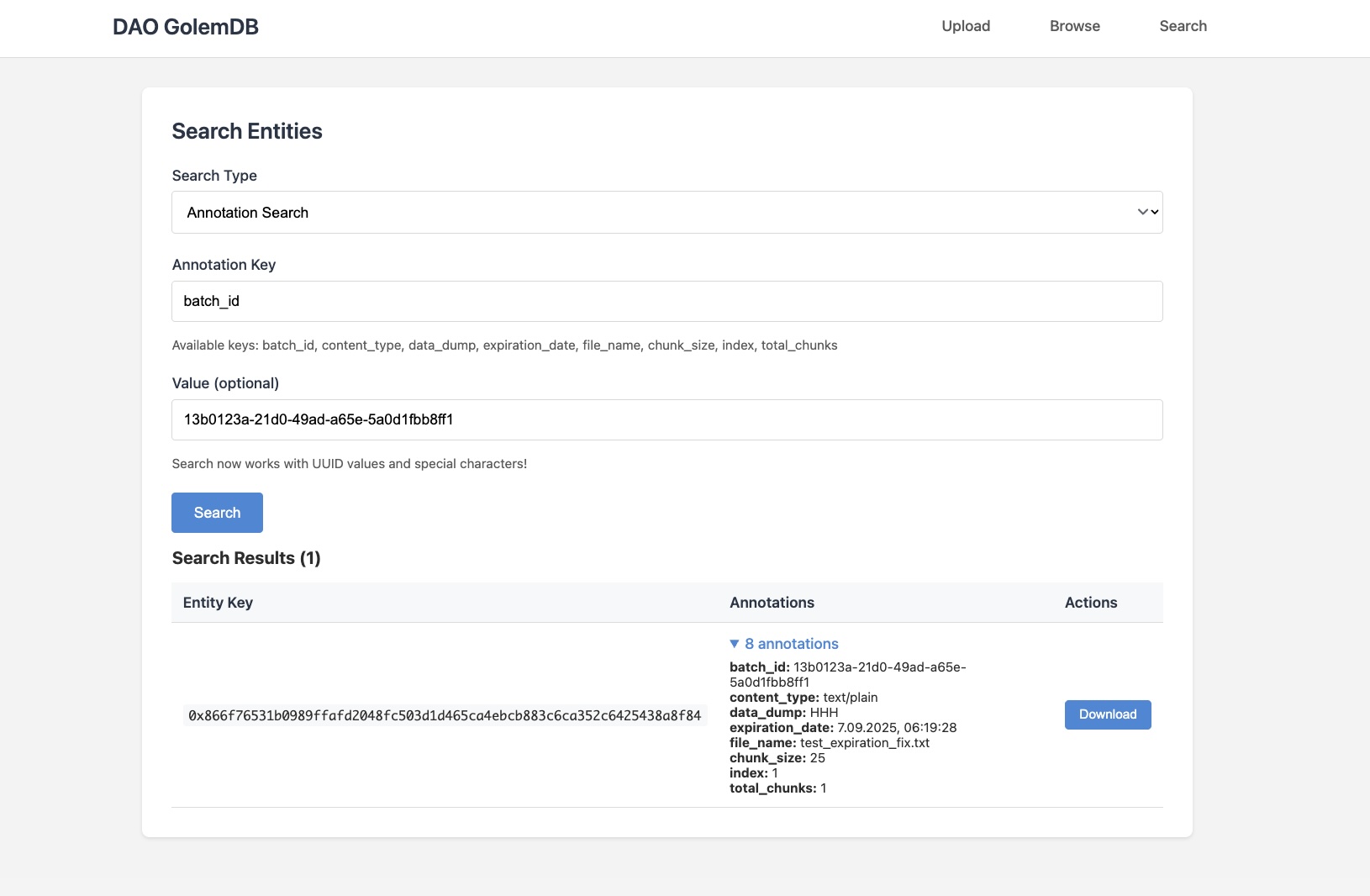
The interface can be usefull for DAOs to upload files in a decentralised manner or scientist to download or publish data dumps on which they can then conduct research. Usage of GolemDB increases availability.
The main idea is to allow users to store very large files on golemDB. The main obstacle to that is the gas limit of single transaction. Currently on hackathon’s testnet we are allowed to push around 120KB of data per transaction. Therefore, our backend would split the file given by the user into many chunks, 100KB each. Every such chunk would be then sent in entity in a separate transaction. To aggregate those scattered across transactions entities, we gave them all the same annotations with unique uuid4 batch_id and string annotation set by user. Also every chunk has index numeric annotation which indicates the order of how chunks were pushed to blockchain.
After pushing all chunks of file data to golemDB our backend then creates one or more additional entities (entity_for_keys) that will be used for automatic aggregation of all chunk entities. entity_for_keys in data segment contains an array with keys for every chunk entity pushed as the part of the file. This is also important for integrity / security reasons as only entity key is truly unique on blockchain. If key arrays is bigger than tx limit of data, we create more enity_for_keys and index them to know the correct order of keys. On the receiving end, we query for annotation “type” with value of “batch_metadata” and appropriate batch_id annotation. Thanks to that we get all relevant entity_for_keys which we then use to extract and sort keys of chunk entities. This allows us to correctly download a large file from golemDB.
Link to repo: https://github.com/aMWerLogic/data_dump_golem-ethxwarsaw2025
Eth addresses:
- 0x6119Cb84698758Bbb9fe9257bF95Ecd7eA8AdF1b
- 0xEc2e9d7f437f4938f70418A35F97d7fa2ED8a16A