Oil Spill Detection by IA
Detección de derrames de petróleo en el océano mediante imágenes satelitales e inteligencia artificial
- 0 Raised
- 681 Views
- 0 Judges
Tags
Categories
Gallery







Description
Detección de manchas de petróleo en el océano mediante imágenes satelitales e inteligencia artificial
OBJETIVO DEL PROYECTO
Metodologías de investigación basadas en la aplicación de la Inteligencia Artificial a la estadística de distribuciones de datos de derrame de petróleo en el mar a partir de imágenes de satélite.
💡MOTIVACIÓN
Los derrames de hidrocarburos en el mar son fenómenos de origen antropogénico que se producen por accidentes en los buques, en el lavado de tanques o en la eliminación de aguas residuales (aguas de sentina), que suelen estar contaminadas con altos niveles de hidrocarburos. Es necesario establecer un sistema eficaz de vigilancia de la contaminación marítima por hidrocarburos, cuya respuesta temprana pueda ayudar a mitigar los efectos nocivos sobre el ecosistema marino e incluso contribuir a disuadir a los buques que provocan los derrames.
INTRODUCCIÓN
La premisa fundamental de esta investigación es explorar diferentes modelos de Inteligencia Artificial (IA) basados en las características estadísticas de los rasgos identificados en las imágenes satelitales SAR, es decir, no pretendemos, en un principio, explorar las características de los píxeles contenidos en las características individualmente sino en las características de la distribución de píxeles de las características en su conjunto. Tampoco pretendemos, en este punto, explorar técnicas avanzadas de aprendizaje profundo utilizadas con fines de detección de objetos. La metodología aquí descrita se basa en fases incrementales y pretende contribuir, per se o de forma complementaria, a otras técnicas de detección de derrame de petróleo en el océano.
El entrenamiento de los modelos de Inteligencia Artificial (IA) de este proyecto se basará inicialmente en un conjunto de datos (DS) ya etiquetado, es decir, con características petroleras y no-petroleras detectadas y segmentadas (o vectorizadas) en imágenes SAR de Sentinel 1A (S1A). Las imágenes son de la región Cantarell/Golfo de México del año 2020 y fueron proporcionadas por cortesía del Dr. Carlos Beisl, de Geo Spatial Petroleum (https://geospatialpetroleum.com), responsable de la descarga de la base Copernicus y el procesamiento de imágenes con miras en la identificación, segmentación y etiquetado de los rasgos. Para ello, utilizó procedimientos empíricos ad hoc, construidos a lo largo de su experiencia en el campo. Además de las imágenes TIFF originales (.SAFE), se generaron imágenes TIFF de 8 y 16 bits, utilizadas en procedimientos de identificación y clasificación de los rasgos. Por rasgo, en este contexto, nos referimos a una porción de la imagen que se destaca de su entorno por alguna razón, sin considerar su identificación de clase. Por segmentación (o vectorización), en este contexto, nos referimos a la generación de polígonos georreferenciados irregulares y cíclicos, que definen un rasgo. Por etiquetado, en este contexto, nos referimos a la clasificación de cada rasgo segmentado, que fue clasificado, en este DS, como mancha de filtración o derrame de petróleo. La figura 1 muestra un ejemplo de un segmento etiquetado extraído de DS.
Las características de los rasgos a extraer se basarán en la revisión de la literatura realizada por Rami Al-Ruzouq et al., que destaca las principales características exploradas por el conjunto de artículos revisados, hasta 2020. Algunos de ellos son fáciles de implementar y otros no tanto, o incluso no aplicables al conjunto de imágenes SAR disponibles en el DS. Las características a extraer se refieren tanto a las características internas de los rasgos como a las externas y al contraste entre la porción interna y externa. Se pueden agregar otras funciones según sea necesario. La Figura 2 muestra las clases de entidades más utilizadas en la revisión. (Consulte el archivo adjunto Características de derrames de petróleo para obtener más detalles)
Para extraer las características de los accidentes en su conjunto, estos deben estar ubicados espacialmente en la imagen SAR, es decir, georreferenciados. En la fase de entrenamiento de los modelos de IA, esta tarea se facilita porque el DS ya tiene las características segmentadas y bastará con georreferenciar y extraer sus características de las imágenes SAR. Sin embargo, para evaluar la metodología será necesario utilizar un segmentador que indique preliminarmente dónde hay porciones de las imágenes que son diferentes a su entorno, generando características segmentadas aleatorias. La idea de las fases iniciales de este proyecto es extraer las características de estos segmentos aleatorios detectados y someterlos a modelos de IA entrenados con las características de los rasgos extraídos del DS, para estimar su clasificación entre derrame de petróleo o mancha de filtración. En este primer momento apostaremos por la capacidad de segmentación de SAM (Segment Anything Model) Versión 2 de Meta.
El desarrollo de este proyecto se llevará a cabo en el lenguaje Python y se llevará a cabo a través de módulos reutilizables, cuando sea relevante, para garantizar la replicabilidad durante las fases del proyecto, como la extracción de características de entrenamiento y prueba y la evaluación de modelos de IA. Tras esta fase inicial, se prevén otras fases como trabajo futuro, con el objetivo de mejorar los modelos de IA y contribuir a reducir los riesgos medioambientales provocados por los vertidos de petróleo.
Como objetivo secundario, este proyecto pretende iniciar desarrollos encaminados a crear un paquete de extracción de estadísticas para facilitar la tarea descrita anteriormente y ponerlo a disposición de la comunidad. La motivación para esto se basa en facilitar la instalación de paquetes para extraer estadísticas, permitir al investigador mantener el enfoque en el objetivo de la investigación y también poder estandarizar los resultados del Análisis Exploratorio de Datos (EDA, en Inglés).
⚙️ Tecnologías espaciales de la UE (DATA)
Los datos para entrenar los modelos de IA fueron proporcionados por el Dr. Carlos Beisl de Geo Spatial Petroleum y consisten en una colección de 408 características múltiples clasificadas e imágenes de 8 y 16 bits procesadas utilizando la metodología empírica del autor. Las imágenes sin procesar provienen del S1A 2020 de la región de Cantarell/Golfo de México.
- Nombre: DS-Cantarell
- Propietario: Dr. Carlos Beisl (Geo Spatial Petroleum, https://geospatialpetroleum.com). No está publicado.
- Satélite y características:
- Satélite: Sentinel 1A (S1A)
- Producto: GRD (Ground Range Detected) Level-1
- Órbita: ascendente y descendente
- Modo de adquisición: IW (Interferometric Wide swath)
- Polarización: VV+VH
- Resolución de píxeles: 10m
- Archivos de imagen
- Número de imágenes: 10 (*)
- Formatos: .SAFE, GeoTIFF de 8 bits y GeoTIFF de 16 bits
- Periodo: sucesos en 2020
- Región: Cantarell / Golfo de México
- Procesamiento: corrección de órbita, ruido térmico, de bordes y geométrico, filtro Frost y calibración para sigma 0dB
- Archivo de segmentos
- Cantidad: 1
- Formato: archivo de forma
- Total de polígonos múltiples: 408 (*)
- Atributo objetivo: CLASSE (CLASE)
- Posibles clases: “DERRAME DE PETRÓLEO” y “SLICK DE FILTRACIÓN”
(*) Una imagen puede tener uno o más polígonos o múltiples polígonos. Un multipolígono se compone de más de un polígono, todos de la misma clase.
NOTA: En la Fase 2 se utilizarán más datos y productos de la línea Sentinel
METODOLOGÍA REALIZADA
FASE 0 - “Análisis Exploratorio de Datos”
Preparar el DS para enviarlo a la IA: como todo trabajo de IA, esta fase tomó alrededor del 80% del tiempo para llevarse a cabo. De las 10 imágenes disponibles pudimos extraer 1.633 casos, que representan el número de polígonos etiquetados en el DS. Entre las características de las características pudimos implementar 59, la mayoría de las cuales se basaron en el artículo base antes mencionado y otras de manera empírica de los autores. El procesamiento de carga generó algunos problemas aún no investigados y esto provocó algunos valores nulos en el DS, los cuales fueron eliminados, dando como resultado 1.589 casos. Las características completas son: ['ID_IMG', 'IMG_NAME', 'YEAR', 'MONTH', 'DAY', 'IDX_VECT', 'ID_VECT', 'IDX_POLYG', 'LOC_POL_BBOX_X1_DEG', 'LOC_POL_BBOX_X2_DEG', ‘LOC_POL_BBOX_Y1_DEG', 'LOC_POL_BBOX_Y2_DEG', 'LOC_POL_BBOX_X1_M', 'LOC_POL_BBOX_X2_M', 'LOC_POL_BBOX_Y1_M', 'LOC_POL_BBOX_Y2_M', 'LOC_CENTR_KM_LAT', 'LOC_CENTR_KM_LON', 'SHP_AREA_KM2', 'SHP_PERIM_KM', ‘SHP_COMPLEX_MEAS', 'SHP_SPREAD', 'SHP_FACT', 'SHP_CIRCUL', 'SHP_PER_AREA_RATIO', 'SHP_HU_MOM1', 'SHP_HU_MOM2', 'SHP_HU_MOM3', 'SHP_HU_MOM4', 'SHP_HU_MOM5', 'SHP_HU_MOM6', 'SHP_HU_MOM7', 'IN_STD', 'IN_VAR', 'IN_MIN', 'IN_MAX', 'IN_MEAN', 'IN_MEDIAN', 'IN_VAR_COEF', 'OUT_STD', 'OUT_VAR', 'OUT_MIN', 'OUT_MAX', 'OUT_MEAN', 'OUT_MEDIAN', ‘OUT_VAR_COEF', 'TEXT_CONTR_GLCM', 'TEXT_HOMOG_GLCM', 'TEXT_ENTRO_GLCM', 'TEXT_CORREL_GLCM', 'TEXT_DISSIM_GLCM', 'TEXT_VAR_GLCM', 'TEXT_ENERGY_GLCM', 'TEXT_MEAN_GLCM', 'SLICK_DARKNESS', 'AREA_KM_DS', 'PERIM_KM_DS', 'CLASSE', 'SUBCLASSE']
Fueron creados con un prefijo que tiene la función de indicar a qué tipo pertenece, son:
- LOC_: significa que la característica está en relación con el posicionamiento geoespacial
- SHP_: significa que la característica está en relación con la forma del rasgo
- IN_: significa que la característica está en relación con las estadísticas internas de la característica
- OUT_: significa que la característica está en relación con las estadísticas externas de la característica (océano)
- TEXT_: significa que la característica está en relación con la textura del rasgo
Resalte para SLICK_DARKNESS, definido por nosotros, que indica cuánto más oscura es la característica en relación con el océano. Las otras características son útiles para posicionamiento y referencia geoespacial y fueron eliminadas del DS de entrenamiento, que por lo tanto tenía una dimensión de 1,589 casos x 39 características.
Comprobación del equilibrio de las clases disponibles en el DS: Se comprobó que el DS no está equilibrado en relación a la clase objetivo (ver figura 3), teniendo la clase DERRAME DE PETRÓLEO muchos más casos que la clase SEEPAGE. Esto puede dañar el rendimiento de los modelos de IA, pero solo se estudiará a medida que este proyecto avance en fases posteriores.
FASE 1 - “Estructuración y Primeros Resultados”
Se crearon scripts para georreferenciar las características etiquetadas, extrayendo las características internas, externas y de contraste de las características, creando imágenes individuales de 8 bits de las características en 2 modos (con y sin el segmento de característica, para enviarlas al segmentador, como en el Ejemplo en la figura 4 a continuación. Sin la función, es útil para enviar al segmentador y con la función se utiliza para comparaciones visuales.
Los scripts para cargar, enviar algoritmos de IA y evaluar los resultados también se generaron y están publicados en nuestro GitHub. Según lo previsto, se desarrollaron funciones para facilitar usos futuros. El DS resultante está en formato CSV (valores separados por comas).
RESULTADOS
Segmentación utilizando SAM2 de META: los resultados de la segmentación de imágenes de 8 bits no funcionaron como se esperaba. Como se muestra en los ejemplos siguientes, no hubo segmentación del rasgos. Hay que considerar, sin embargo, que la versión de SAM2 utilizada fue la que genera modelos automáticos y fue enviada con la parametrización predeterminada. Hay posibilidades de optimizar los parámetros y también utilizar SAM2 como indicador, lo que permite otro nivel de optimización. La Figura 5 muestra 4 ejemplos de intentos de segmentación de características utilizando SAM2, debido a su similitud con objetos de la vida real a los que recibieron el apodo. Para cada característica a) Pato, b) Monstruo, c) Panamá y d) Cruz, la imagen de la izquierda se refiere a la imagen enviada a SAM2, la imagen del centro es el resultado de la segmentación y la de la derecha es la característica objetivo, que debe segmentarse.
Sometimiento del DS a algoritmos de IA: Se realizaron pruebas con 3 algoritmos de IA. Random Forest del paquete SciKit Learn, XGBoost y Random Forest del paquete XGBoost. La preparación del DS para el envío a los algoritmos se realizó mediante una función disponible en SKLearn, recibe las características predictivas y también la clase objetivo y, en este caso, según la parametrización, está devolviendo el conjunto de datos de entrenamiento con el 80% de el tamaño total del DS original y el conjunto de datos de prueba con un 20%.
X_train, X_test, y_train, y_test =
train_test_split(DS[features[:-1]], DS['CLASSE'], test_size=.2)Los modelos fueron creados de la siguiente manera:
model1 = RandomForestClassifier() model2 = xgb.XGBClassifier() model3 = xgb.XGBRFClassifier()
Cada uno de ellos fue sometido a entrenamiento con los conjuntos de datos de entrenamiento, que fueron de corta duración, alrededor de 5 segundos.
model1.fit(X_train, y_train) model2.fit(X_train, y_train) model3.fit(X_train, y_train)
Luego se evaluó lo siguiente:
y_pred = model.predict(X_test) acc = metrics.accuracy_score(y_test, y_pred)
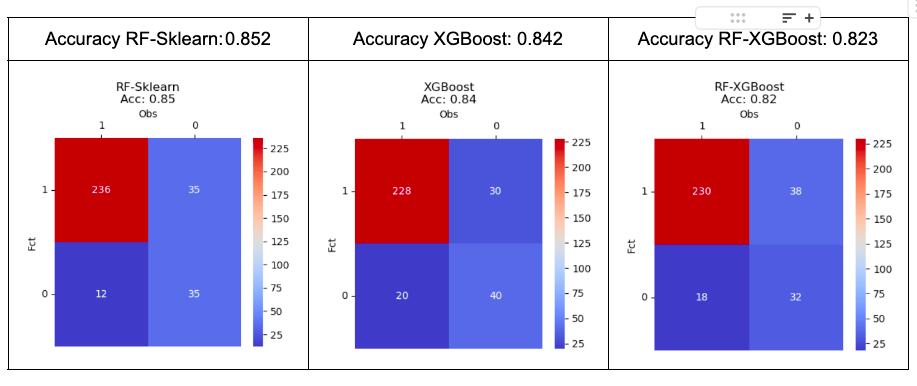
Como se puede ver en la siguiente tabla, el algoritmo Random Forest del paquete Sk-Learn tuvo el mejor rendimiento, seguido por los algoritmos XGBoost y Random Forest del paquete XGBoost. Vale la pena considerar que los modelos no fueron optimizados sino ejecutados con sus parámetros predeterminados. La tabla también muestra la Matriz de Confusión para cada evaluación. Debemos considerar el desequilibrio de clases reportado anteriormente, cuando esto sucede, el rendimiento de la generalización disminuye.
Como se muestra en la figura 6, también se realizaron cálculos de la importancia de las variables sobre el desempeño de los modelos de IA, es decir, cuánto influyó cada característica en el resultado. Este tema es de vital importancia ya que puede eliminar características innecesarias y merece más estudio.
TRABAJO FUTURO
Las futuras fases de desarrollo se basan en ampliar la aplicación de la metodología, tanto en términos de modelado como de algoritmos de IA, según la versión 1 de este documento, que describe la planificación:
- La inclusión de datos meteoro-oceanográficos asociados a las características del DS, a los que llamamos datos auxiliares
- Comprobar si al incluir el posicionamiento del rasgo en la imagen en relación al origen de la señal serían datos que ayudarían al modelo o no
- Utilice imágenes S1A para otros casos de accidente cerebrovascular en la misma región de DS y en otras regiones
- Utilice imágenes de otros satélites para otros casos de derrames, en cualquier región
- Si las metodologías basadas en segmentadores no funcionan, podemos utilizar enfoques de comparación píxel a píxel, agrupando posteriormente los píxeles cercanos utilizando un umbral preestablecido.
- Considere los dos enfoques de clasificación, mediante la distribución en su conjunto y píxel por píxel.
- Combinando enfoques de visión por computadora (CV) como YOLO y redes neuronales convolucionales (CNN) de aprendizaje profundo (Deep Learning, DL)
- Aplicar otros métodos de comparación de distribución que no sean de IA
- Combine modelos que generen pronósticos utilizando conjuntos de diferentes metodologías, como arranque, embolsado y apilamiento.
El desarrollo de las siguientes fases requerirá investigaciones adicionales sobre temas como:
- Transferir aprendizaje
- Investigación sobre la conversión de señales de diferentes satélites/sensores mediante IA
- Procesamiento automático de imágenes digitales (PDI) para hacer coincidir el nivel de procesamiento de nuevas imágenes con las imágenes utilizadas en el entrenamiento
- Técnicas de conjunto de IA
🚀 Challenges and our project
Contribution of this project to disaster risk reduction.
- Challenge 2) Prevent and prepare for future disasters: helps identify, as soon as possible, oil spills in the ocean that may reach the coast
- Challenge 3) Preserve biodiversity and threatened habitats: helps identify possible suspects of marine oil pollution, enabling deterrence
👥 Equipo (TEAM)
Dinos quién forma parte de tu equipo, qué función desempeña (por ejemplo, programador/diseñador) y una biografía de 1 a 2 frases.
- José Roberto M. Garcia (he, him): Consultant, programmer and IT and AI enthusiast. He holds a PhD in machine learning for meteorology and works in R&D at INPE/BR developing solutions to solve environmental science problems. He has knowledge in Python, R, shell scripts, geoprocessing, AI modeling and algorithms, databases, etc. Interested in seeking solutions based on cutting-edge technologies and AI to contribute to the mitigation of damages caused by climate change.
- Maria Paula Graziotto (she, her): Ocean consultant and programmer. She holds a master's degree in physical oceanography and is currently pursuing a PhD. She has participated in projects to address marine oil pollution problems in the ocean. She has knowledge of Python, shell scripts, geoprocessing, AI algorithms, databases, etc.
- Bruna Leal (she, her): IT and AI consultant and programmer. PhD in computer engineering, developing IT and AI solutions to solve environmental science and other problems. Currently pursuing a post-doctorate. Has knowledge in Python, shell scripts, geoprocessing, AI modeling and algorithms, databases, etc.