- 10,889 Raised
- 476 Views
- 1 Judges
Team
Categories
Gallery

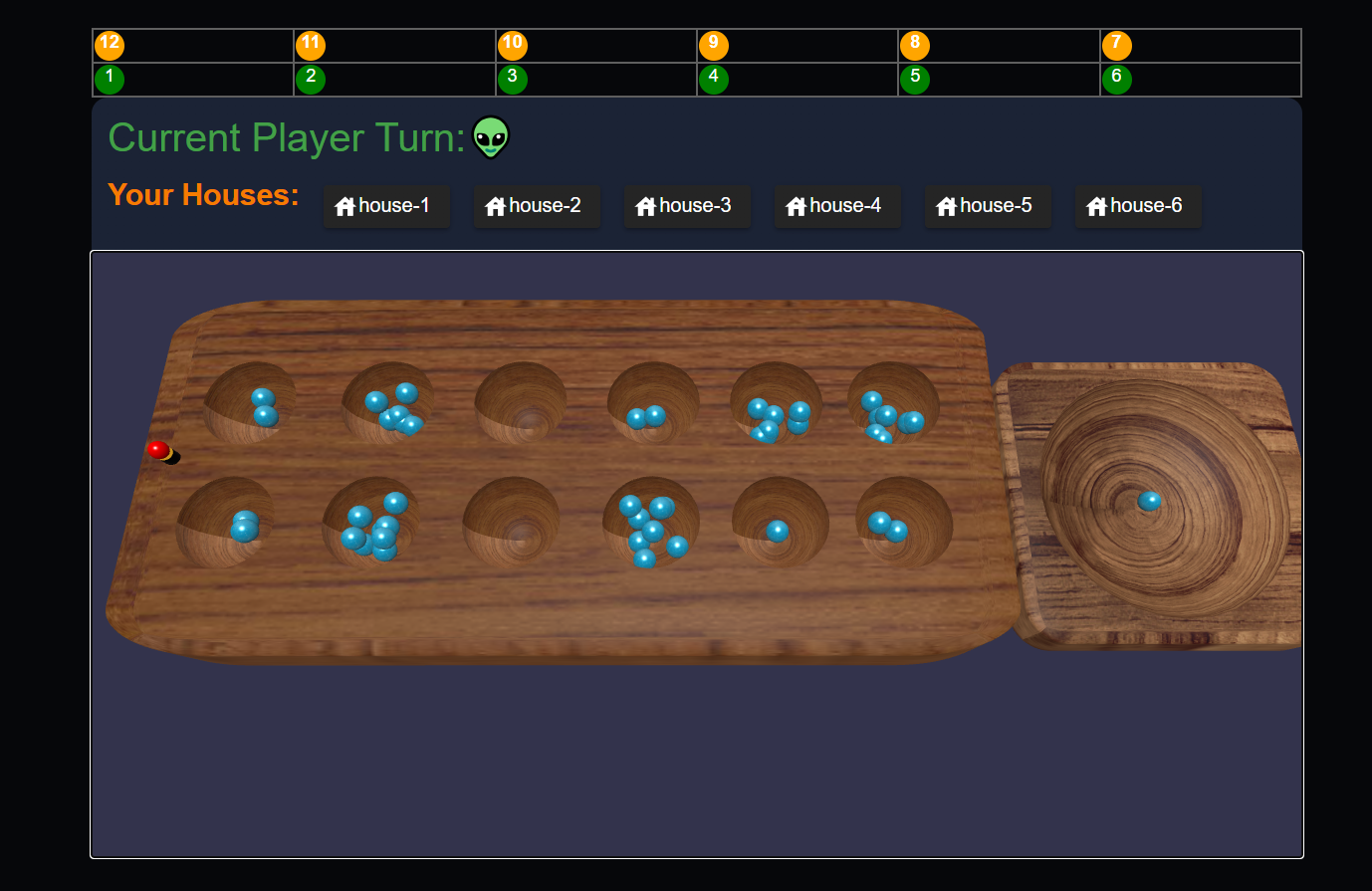
Description
Implementation of Strategic Gameplay AI Agent on Cartesi Rollup
Oware: A Strategic Board Game
Oware, is a strategic board game. It's known for its simple rules and surprisingly deep gameplay, making it a perfect choice for players of all ages and skill levels.
The Essentials of Oware:
The Board: Oware is played on a board with two rows of six pits (houses) on each side. In the center of each player's side sits a larger pit called the "mancala" (or scoring pit).
The Seeds: Forty-eight seeds,initially placed in the houses, with four in each house.
The Sowing: Turns alternate between players. On your turn, you choose one of your houses that contains seeds. You pick up all the seeds from that house and proceed to sow them, one by one, into each subsequent house in a counter-clockwise direction.
Capturing Seeds: If your last sown seed lands in an empty pit on your side that is directly opposite an opponent's pit containing one or two seeds, you capture those seeds and place them in your mancala.
The Objective: The game continues until all seeds have been sown and captured. The player with the most seeds in their mancala at the end is declared the winner.
Oware's Charm:
Simple Rules, Deep Strategy: Oware's elegance lies in its easy-to-learn rules that quickly unlock a surprising amount of strategic depth. Planning your sowing sequence, anticipating your opponent's moves, and setting traps for captures are all crucial elements of mastering the game.
A Timeless Tradition: Oware has been enjoyed for centuries, carrying a rich cultural heritage. Playing Oware connects you to a long line of strategists who have honed their skills on this classic board game.
A Game for Everyone: Oware is perfect for casual and competitive players alike. It's a fantastic choice for family game nights, friendly challenges with friends, or simply a relaxing mental exercise.
Background
Strategic Gameplay AI Agent: This document outlines the implementation of a strategic gameplay AI agent designed to play Oware and make strategic decisions within the game.
Key Technologies:
Front-End (React & Vite):
Built with React for a user-friendly interface.
Game Board (Blender & Babylon.js):
Blender: A free and open-source 3D modeling software used to create custom models for the Oware game board.
Babylon.js: 3D and WebGL engine to render the game board within the web browser.
Back-End & Security (Cartesi Rollups & Docker):
Cartesi Rollups:
Docker
AI Opponent (Deep Learning):
Integrates a pre-trained deep learning model to create a strategic AI opponent that challenges players.
System Architecture
High-Level Overview:
The architecture includes components such as the AI agent, communication layer, and interaction with Cartesi rollup.
The Oware game on Cartesi Rollup utilizes the two-tier architecture:
Front-End:
This user-facing interface allows players to interact with the game. It is implemented as:
A web application providing a graphical user interface (UI).
Back-End (Verifiable Logic):
This layer executes within the Cartesi Rollups infrastructure. It ensures verifiable game logic and state management:
Stores and updates the Oware game state based on user input received from the front-end.
Employs the deep learning model to analyze the current game state and select the optimal move for the AI opponent.
Generates two key outputs:
Vouchers: These represent transactions that can be executed on the Ethereum mainnet (Layer 1) for permanent game state updates.
Notices: These convey information like move and game updates, verifiable on Layer 1 without requiring full game state recreation.
3. Deep Learning Model
The core of the AI opponent is a deep learning model built using Keras. Refer to the companion document (document here) for a detailed description of the model architecture, training configuration, and considerations specific to Oware.
4. Integration with Cartesi Rollups
The deep learning model resides within the verifiable logic layer on Cartesi Rollup. This ensures:
Security: Game logic and state transitions are verifiable on the Ethereum mainnet, preventing manipulation by the back-end.
Scalability: Computationally intensive tasks like model evaluation are offloaded from Layer 1, improving overall game performance.
By combining a deep learning model with Cartesi Rollup infrastructure, the system offers a secure, scalable, and privacy-preserving platform for playing Oware with an AI opponent. The verifiable nature of the back-end logic guarantees fair gameplay while leveraging the benefits of blockchain technology.
AI Agent Component:
The AI agent generates gameplay decisions based on learned strategies.
The model leverages Keras library, to construct and train a neural network for effective move selection.
Model Architecture
The model employs a sequential architecture, stacking layers for information processing. Here's a breakdown of the layers:
Dense Layers: Three Dense layers are used, with the number of neurons in each layer to be determined through experimentation.
The first layer transforms the input board state representation into a higher-dimensional space, potentially capturing features like seed counts and capture opportunities.
ReLU (Rectified Linear Unit) activation for introducing non-linearity and improving model expressiveness.
Subsequent layers extract increasingly complex features from the game state.
Dropout Layers: Dropout layers are incorporated after each Dense layer to prevent overfitting, especially when training data might be limited. A dropout rate of 10% (0.1) is the starting point.
Output Layer: The final layer has a number of neurons equal to the number of valid moves possible in a given Oware state.
A softmax activation function . Softmax transforms the output layer's activations into a probability distribution over all possible moves. This allows the model to select the move with the highest predicted value.
Training Configuration
Optimizer: Stochastic Gradient Descent (SGD) is used for optimizing the model's weights during training. However, exploring other optimizers like Adam could potentially lead to faster convergence.
Loss Function: Categorical Crossentropy loss is used. It measures the difference between the model's predicted move probabilities and the actual distribution representing the best move.
Training: Training success depends on a large number of Oware games. Real human game data or simulated games can be utilized for this purpose. Th folder oware-agents-models contains some trained models.
Evaluation
The model's performance will be evaluated by playing against different Oware AI opponents or human players. Metrics like win rate and average game score will be used to assess its effectiveness.
This deep learning model provides a foundation for building a strong Oware-playing agent. Through careful adjustments to hyperparameters, input representation, and potentially incorporating reinforcement learning approaches, the model can be refined to achieve a high level of strategic play in Oware.
To learn more about the specific code used to create and train this model, please refer to this document.
Running the Oware DApp
Prerequisites:
Ensure you have a Cartesi Rollups environment in host mode set up and running. Refer to Cartesi documentation for specific instructions.
Install Sunodo:
Follow the official Sunodo installation guide to install Sunodo on your system. You can find the guide at Sunodo Installation Guide (guide).
Build the DApp:
Navigate to the directory containing your Oware DApp code (likely named my-app). Once there, run the following command in your terminal:
sunodo build
This command will build the DApp for deployment on the Cartesi Rollups infrastructure.
Run the DApp:
While still in the my-app directory, execute the following command to start the DApp:
sunodo run
This will deploy and run the Oware DApp on your local Cartesi Rollups environment in host mode
Install and Run the Front-End:
Change directories to the folder containing your front-end code (likely named client).
Within the client directory, install the required dependencies using npm:
npm install
Once the installation is complete, you can start the front-end server (assuming it uses a command like npm start):
npm run dev
This document an overview of the strategic gameplay AI agent implemented on Cartesi rollup, enabling secure and scalable deployment of AI-powered gameplay experiences.